올해 인터넷 업계의 가장 큰 이슈를 말하라면 아마도 ‘검색열풍’일 것이다. 2002년 검색수익모델이 비약적으로 성장하면서 온라인 포탈의 확실한 수익 원으로 자리 잡은 검색은 국내외적으로 올 한 해를 뜨겁게 달군 그야말로 ‘핫이슈’였다.
국내의 경우 네이버는 뉴스그룹 형태의 게시판을 ‘지식인’으로 마케팅 하면서 야후!를 제치고 확실한 선두권을 확보하였으며 이에 긴장한 다음은 구글과 손을 잡으며 검색의 질을 높이는 한편, 다음의 최대 자랑인 카페를 활용한 카페검색을 통해 순식간에 검색분야 2위를 탈환하는 기염을 토했다.
국외적으로는 구글의 열풍을 들 수 있다. 단순히 소프트웨어 회사로만 인식되던 구글은 ‘많이 인용된 문서가 좋은 문서’라는 참신한 아이디어를 통해 페이지랭크라는 검색기법을 가지고 연 5억 달러의 매출과 1억5000만 달러의 순익을 올리며 고속 성장을 구가하였고, 04년 초 IPO에 등록한다는 계획을 선언하기에 이르렀다.
앞서도 이야기했지만 검색에 대한 열풍은 그것이 돈을 벌어준다는 것에 기인한다. 03년 국내 키워드 광고 성장률은 작년도 대비 277% 규모로 성장하고 있으며 전체 인터넷 광고시장의 약 49%에 이르고 있다. 금액으로 따지면 1천억 원이 조금 넘는 수치다.
내년도 역시 지속적인 성장이 예측되는 가운데 04년 검색의 화두는 ‘Context 검색’이 될 전망이다. 키워드 검색 광고 시장의 성숙환경을 기반으로 추가적인 수익 모델 창출을 위한 다각화 방안의 일환으로 검색자의 위치정보를 기본 CONTEXT로 하는 지역생활 정보시장의 키워드 검색형 수용이 적극 모색되고 있으며, 국내의 경우 네이버와 다음은 지역정보 사업자와의 접촉을 강화하고 있고 구글 역시 ZIP Code, IP Addr., Registered Inf.에 의한 개인별 맞춤정보 제공을 내년도 방향으로 잡고 있다.
이런 상황에서 필자는 마이크로소프트의 검색에 대한 행보가 많이 궁금했었다. 마이크로소프트는 네스케이프와 리얼네트웤스 등 주목 받으며 자라나는 싹을 인수하거나 아니면 시장에서 아예 없애버리는 전략을 가진 회사가 아닌가? 그런 마이크로소프트가 이처럼 뜨거운 시장을 묵묵히 지켜만 보고 있다는 것이 필자를 더욱 더 궁금하게 만든 요인이었다.
그러던 중, 얼마 전 CNET을 통해 마이크로소프트의 검색프로젝트인 SIS(Stuff I’ve Seen)가 소개 되었고, 이를 오늘 데이빗앤대니 독자 분들과 나누고자 한다. 결론부터 말하자면 SIS는 구글이나 오버추어처럼 웹 기반 검색이 아니라 클라이언트 내부에서 돌아가는 검색이다. 그러니까 윈도우즈의 ‘탐색’ 같은 것이다.
구글과 맞서는 멋지고 새로운 검색을 가지고 이번엔 또 어떻게 싸우려 하는지 흥미진진했던 필자는 다소 실망한 것이 사실이다. 그러나 10월 31일 뉴욕타임즈는 마이크로소프트가 구글의 인수를 위해 2개월간 물밑 접촉을 하고 있으며 구글을 자사의 윈도우 차기 작에 삽입하려는 계획을 갖고 있다라고 보도했다. 그렇다면 윈도우 사용자들은 내부에서 SIS를 통해 검색을 하고 외부로의 확장은 구글을 쓰게 되는 것이다.
물론 구글의 인수가 쉽지 않을 것이다. 구글은 약 150억∼250억 달러의 기업가치를 갖는 것으로 전망되고 있고, 내년 초에 IPO 계획까지 가지고 있기 때문에 당장 돈이 아쉬운 회사가 아니다.
경제적 측면 외에도 구글은 블로그의 인수를 시작으로 Applied Semantics, Kaltix 등을 연달아 인수하고 최근에는 Friendster 인수까지 적극적인 움직임을 보이는 등 자사만의 중장기적 전략방향을 확실히 갖고 있는 회사이기 때문이다.
주제가 좀 벗어났는데, 아무튼 마이크로소프트의 SIS에 대해 잠시 살펴보도록 하자. 본 글의 하단에 SIS 프로젝트의 시니어 연구원인 Susan Dumais의 PPT 발표자료를 첨부하였으니 자세한 것은 이를 다운로드 해서 보시면 좋을 것이고 본 글에서는 대략적인 설명만 하는 것으로 한다.
SIS를 이해하는 두 가지 키워드는 ‘컨택스트’와 ‘윈도우즈’다. 컨택스트는 데이빗앤대니에서 많이 이야기 한 주제이므로 상단에 링크를 참조하시면 의미를 쉽게 알 수 있을 것이고, SIS에서 말하는 컨택스트는 사용자의 검색 결과에 대한 컨택스트, 그러니까 사용자의 윈도우즈에 기록된 정보들을 바탕으로 우선순위를 결정한다는 것이다. 구글이나 오버추어에서 말하는 로케이션 기반 컨택스트와는 다르다.
윈도우즈, 마이크로소프트의 관심은 ‘윈도우즈에 멋지게 들어가는 것이 앞으로 무엇이 있을까?’ 이다. 윈도우즈 소프트웨어에는 개인의 웹서핑 기록과 관심, 아는 사람들의 연락처 정보, 일과 스케쥴에 대한 기록들, Work 프로젝트, 그리고 여러 가지 다양한 데이터들이 담겨 있다.
이를 토대로 해서 어떤 것을 검색할 때에 무엇이 연관성이 높고 낮은지를 파악하는 것이다. 즉 ‘SIS란 윈도우즈에 담겨 있는 정보들을 기초로 하여 검색 시 모든 파일들을 검색하여 사용자가 전에 보았던 정보 중 어떤 것이 더 중요한지를 결정하여 검색결과에 출력하는 시스템’으로 보면 크게 틀리지 않다.
SIS(Stuff I’ve Seen)는 5개의 메인 콤포넌트로 구성이 되는데 Gatherer, Filter, Tokenizer는 새로운 파일포맷을 핸들링 하도록 파일 포맷을 해독하는 역할을 하고. Indexer는 빠른 검색을 위해 인덱싱 하는 역할을 하며 Retriever는 Boolean 지원, 문장 검색, 근접 검색 등을 가능하게 한다. 메타데이터에는 작성일, 작성자, 제목, 크기 등등이 포함된다.
모든 콤포넌트들은 클라이언트에서 동작한다. 기본적으로 유저의 메일 프로파일, 웹 캐쉬, 개인적인 파일들(미디어 파일을 포함)과 함께. 인덱싱은 자동적으로 업데이트 되는데 새로운 메일이 왔을 때나 웹 페이지를 볼 때, 새로운 문서를 작성할 때 등이다. 클라이언트에서 작동하고 로컬 파일들을 뒤지기 때문에 쿼리에 대한 응답속도는 빠르다.
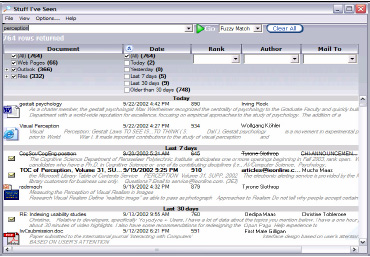
SIS의 화면이다. 화면이 좀 작아서 잘 보이지 않겠지만 좌측 맨 위가 검색 창이고 검색창 옆에는 퍼지매치 등의 검색조건 드롭박스가 위치한다. 그 아래 메뉴바처럼 생긴 바에는 도큐멘트/날짜, 랭크, 작가, Mail to가 있고 도큐멘트 조건은 ALL, 웹 페이지, 아웃룩, 파일 등이며 날짜는 모두, 오늘, 어제, 7일~30일 사이가 있다.
아래에는 검색결과가 보이는데 파일형태 썸네일하고 제목, 날짜, 프리뷰 내용이 있다. 만약 메일을 보내거나 받은 것이라면 주고 받은 사람도 나타난다.
이 프로젝트는 마이크로소프트 리서치의 Adaptive Systems and Interaction의 시니어 연구원인 Susan Dumais에 의해 주도되고 있다. 그녀가 CNET과의 인터뷰 한 내용을 보면 SIS의 비전을 가늠할 수 있는데 ‘나에게 빌 게이츠와의 미팅이 있음’이라는 정보는 매우 중요하다. 내 컴퓨터는 빌 게이츠가 우리 조직의 수장이라는 것을 알고 있고 이를 중요하게 취급할 것이다.’라고 말하고 있다.
이를 통해서 마이크로소프트가 생각하는 검색은 ‘검색이 별도로 존재하는 것이 아니라 윈도우즈 안에 있어야 하며, 검색결과는 윈도우즈 내부의 정보들과 외부의 정보들 모두가 포함되어야 하고, 그것의 우선순위는 윈도우즈 안에 기록된 메타데이터들을 바탕으로 추론되어야 한다’ 정도로 요약할 수 있다.
SIS는 완성된 솔루션이 아니다. 현재 1,000명 이상의 내부 직원들이 테스트 중에 있다고 한다(아마도 Longhorn 버전에 추가될 것이라는 예측이 많다). 이것이 어떤 모습으로 우리들에게 다가올 지 아직은 모르겠지만, 그리고 구글을 인수해서 SIS와 연동시킬 수 있을지 없을지 모르겠지만 마이크로소프트의 검색에 대한 전략과 실천방법은 우리에게 매우 흥미진진한 이야기꺼리로 다가올 것임이 분명하다. 2003-12-06