
그래프 데이터베이스는, 지식그래프와 같이 관계 중심의 데이터 구조를 빠르고 확장이 유연하며 복잡한 연결 탐색과 의미 기반 검색을 가능하게 하기에 LLM 등장과 함께 복합적 사용자 질의에 대응하기에 유리한 위치에 있다.
그리고, 랭체인의 일부인 LLM Graph Transformer를 통해, 문장으로부터 그래프 데이터 화 할 수 있는 방법이 2024년 말부터 활발히 공유되기 시작하면서 금융, 법률 등의 복잡한 정보 구조를 다루는 분야에서 적극적으로 검토되고 있다.
벡터 검색을 기반으로 하는 일반적인 RAG는 여러 엔티티 간 관계를 추론해야 하거나, 텍스트 기반의 구조적 연산 (정렬, 집계 등의)이 필요한 질문에 답할 수 없는 한계가 있다. 이것을 그래프 구조로 바꾸면 [엔티티 <> 관계 <> 엔티티] 구조로 연결이 되기 때문에 멀티홉 리즈닝 (multi-hop reasoning, 다중 엔티티 간 연결 추론, 여러 개의 하위 질문으로 나눠서 각 하위의 답을 조합하여 최종 답변을 도출)이 가능하고, 관계 기반의 필터링, 정렬, 합계 등 일종의 SQL 같은 연산 수행이 가능해진다.
예를 들어 ‘서울에 있는 고객사 리스트는?’이라는 질의에 백터기반 RAG는 ‘서울’이 포함된 문장을 검색한다면, 그래프 기반 RAG에서는 [Node (고객사) > IN_CITY > 서울] 관계를 기반으로 답변을 생성하게 된다.
여기서 홉(HOP)이란, 하나의 노드(엔티티)에서 다른 노드까지 가는 연결 수를 의미하는데 예를 들어 마리 퀴리 – (결혼) > 피에르 퀴리 – (수상) > 노벨상 = 2홉 (중간에 피에르 퀴리를 거침).
Neo4j (니오포제이)
Neo4j는 데이터를 노드와 엣지(관계)로 표현하는 가장 널리 사용되는 그래프 데이터베이스(Graph DB)다. 기존 RDB는 행과 열 구조인 반면 Neo4j는 객체 간 관계를 중심으로 저장한다. 사람 A가 회사 B에 다닌다를 표현한다면 –
(:Person {name: “A”}) -[:WORKS_AT]-> (:Company {name: “B”})
그래서 이것의 장점은 RDB JOIN에 비해 수백만개의 관계도 빠르게 조회가 가능하고, DB를 바로 그래프 형태로 시각화 시킬 수 있으며, 랭체인이나 GPT, LlamaIndex(라마인덱스)와 연동이 쉽다.
Neo4j 데스크탑에서 실행한 샘플 쿼리
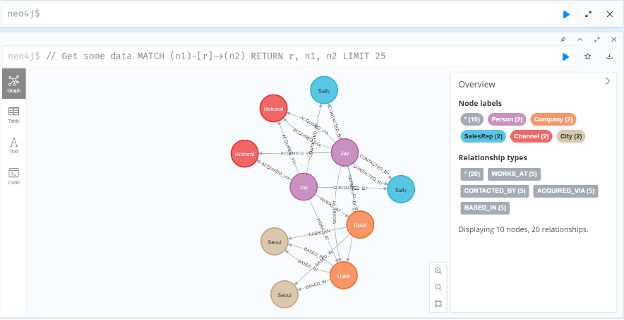
CREATE (:Person {name: “Jay”, title: “PM”});
CREATE (:Company {name: “Upbit”});
CREATE (:City {name: “Seoul”});
CREATE (:SalesRep {name: “Sally”});
CREATE (:Channel {type: “Referral”});
Cypher (그래프쿼리)
싸이퍼는 Neo4j에서 직접 개발한 그래프 전용 질의로 SQL처럼 관계형 데이터가 아니라 노드, 관계, 속성으로 쿼리를 작성할 수 있다. 사실상 그래프 디비 쿼리의 표준이라고 볼 수 있다.
MATCH (p:Person {name: "Jay"}), (c:Company {name: "Upbit"})
CREATE (p)-[:WORKS_AT]->(c);
MATCH (c:Company {name: "Upbit"}), (city:City {name: "Seoul"})
CREATE (c)-[:BASED_IN]->(city);
MATCH (p:Person {name: "Jay"}), (rep:SalesRep {name: "Sally"})
CREATE (p)-[:CONTACTED_BY]->(rep);
MATCH (p:Person {name: "Jay"}), (ch:Channel {type: "Referral"})
CREATE (p)-[:ACQUIRED_VIA]->(ch);
(Jay)-[:WORKS_AT]->(Upbit)-[:BASED_IN]->(Seoul)
|-[:CONTACTED_BY]->(Sally)
|-[:ACQUIRED_VIA]->(Referral)Jay가 Upbit에 재직 중이라는 관계를 연결, Upbit 회사는 Seoul에 있음, Jay는 Sally 영업 담당자에게 연락을 받음, Jay는 Referral 채널을 통해 유입됨. 유입 경로, 담당자, 소속 회사, 지역 등을 그래프 탐색 기반 질의로 추적 가능하게 된다. 예:“Referral 채널로 들어온 사람 중, 서울에 있는 회사를 다니는 사람은?” 답은 Jay.
LLM 그래프트랜스포머
그래프 트랜스포머는 LangChain에서 제공하는 파이썬 기반 클래스로 다양한 종류의 LLM(OpenAI, Anthropic, HuggingFace 등)을 활용해 문서에서 그래프 구조(엔티티+관계)를 추출하는 유연한 도구다. 즉, 사람이 일일이 엔티티 태깅을 하지 않더라도 자동으로 사람/회사/관계 정보 등을 추출해서 그래프 데이터베이스를 생성할 수 있다. 이렇게 생성된 데이터의 저장은 앞서 이야기 한 Neo4j에 저장한다.
자연어 문장 예시: “Jay는 Upbit에서 PM으로 일한다. 그는 Sally라는 영업담당자에게 연락을 받았으며, Referral을 통해 유입되었다. Upbit 본사는 서울에 위치해 있다.”
위 문장을 그래프트랜스포머로 추출하는 코드는 아래와 같다.
from langchain_experimental.graph_transformers import LLMGraphTransformer
from langchain.chat_models import ChatOpenAI
# LLM 및 Graph Transformer 설정
llm = ChatOpenAI(model="gpt-4", temperature=0)
transformer = LLMGraphTransformer(llm=llm)
# 입력 문장
text = "Jay는 Upbit에서 PM으로 일한다. 그는 Sally라는 영업담당자에게 연락을 받았으며, Referral을 통해 유입되었다. Upbit 본사는 서울에 위치해 있다."
# 문장 → GraphDocument 변환 시도
graph_documents = transformer.convert_to_graph_documents([text])
graph_documents[0].to_dict()
LLM Graph Transformer로 추출된 결과 :
GraphDocument(
nodes=[
Node(id="Jay", type="Person", properties={"title": "PM"}),
Node(id="Upbit", type="Company"),
Node(id="Sally", type="SalesRep"),
Node(id="Referral", type="Channel"),
Node(id="Seoul", type="City")
],
relationships=[
Relationship(source="Jay", target="Upbit", type="WORKS_AT"),
Relationship(source="Jay", target="Sally", type="CONTACTED_BY"),
Relationship(source="Jay", target="Referral", type="ACQUIRED_VIA"),
Relationship(source="Upbit", target="Seoul", type="BASED_IN")
]
)
Neo4j에 삽입 (LangChain으로) :
from langchain_community.graphs import Neo4jGraph
from langchain_experimental.graph_transformers import LLMGraphTransformer
from langchain.chat_models import ChatOpenAI
# Neo4j 연결
graph = Neo4jGraph(
url="bolt://localhost:7687",
username="neo4j",
password="your-password"
)
# LLM 및 Transformer 설정
llm = ChatOpenAI(model="gpt-4")
transformer = LLMGraphTransformer(llm=llm)
# 문서 입력
docs = [
"Jay는 Upbit에서 PM으로 일한다. 그는 Sally에게 연락받았으며, Referral로 유입되었다. Upbit 본사는 서울에 있다."
]
# 문서 → 그래프 추출
graph_documents = transformer.convert_to_graph_documents(docs)
# Neo4j로 업로드
graph.add_graph_documents(graph_documents)
마지막으로 질의의 경우, Cypher로 질의하거나 시각화해서 볼 수 있으나 당연히 질의 역시 자연어로 질의 > 싸이퍼 생성 > 답변 생성으로 가능하다.
[자연어 질문] > [LLM + 프롬프트 or LangChain 에이전트] > [Cypher 쿼리 자동 생성] > [Neo4j에서 실행 → 결과] > [LLM이 결과를 자연어로 다시 설명] > [사용자에게 응답]예시) 사용자 입력: “Jay는 어디에서 일하나요?”
LLM이 생성한 Cypher 쿼리:
MATCH (p:Person {name: “Jay”})-[:WORKS_AT]->(c:Company)
RETURN c.name;
결과: Upbit
LLM 응답: “Jay는 Upbit에서 근무합니다.”
그런데, 여기서 자연어 > 싸이퍼 퀴리에 비해 1단계를 더 거치지만 자연어 > 제이슨 > 싸이퍼 구조로 만들게 되면 멀티홉과 조건 기반 쿼리에 유리(“filter”: {“city”: “Tokyo”, “channel”: “Referral”} 등 명시 가능)할 수 있고, 엔티티를 어떤 구조로 이해했는지 바로 알 수 있는 장점이 있다.
“Jay가 일하는 회사는 어디야?” > 아래 제이슨 > 싸이퍼 > Neo4j
{
"source": { "type": "Person", "name": "Jay" },
"relationship": "WORKS_AT",
"target": { "type": "Company" }
}위 구조로 Cypher를 정확한 템플릿으로 만들 수 있음. 즉, “GPT야, 먼저 네가 문장을 어떻게 이해했는지 알려줘(JSON)” 라는 단계가 들어감으로써 서비스 레벨을 올릴 수 있게 된다.
LLM 엔티티 추출
조금 결이 다른 이야기지만, LLM으로 엔티티를 추출할 수 있다. 위에서 설명한 것처럼 문장으로부터는 Graph Transformer를 통해 가능하고, 짧은 “키워드” 하나만으로 엔티티를 추출하려면 Prompt 기반 Slot-Filling 형태가 더 적합하다. 혹은 def extract_keyword_entities와 같은 함수 (WRAPPER(LangChain with_structured_output()) 형태)로도 가능하다.
사용자 키워드: “다이소 전동 눈썹정리기 추천”
(JSON)
{
"brand": "다이소",
"product_name": "전동 눈썹정리기",
"category": ["눈썹정리기", "전동제품"],
"intent": "추천",
"attributes": ["저가", "휴대용", "전동"]
}이것을 다시 그래프 디비화 하면 아래와 같다.
(:Product {name: "전동 눈썹정리기"})
├─[:BELONGS_TO_BRAND]→ (:Brand {name: "다이소"})
├─[:BELONGS_TO_CATEGORY]→ (:Category {name: "눈썹정리기"})
├─[:BELONGS_TO_CATEGORY]→ (:Category {name: "전동제품"})
├─[:HAS_INTENT]→ (:Intent {name: "추천"})
├─[:HAS_ATTRIBUTE]→ (:Attribute {name: "저가"})
├─[:HAS_ATTRIBUTE]→ (:Attribute {name: "휴대용"})
└─[:HAS_ATTRIBUTE]→ (:Attribute {name: "전동"})“어떤 엔티티가 더 필요한지”는 결국 사람이 정해줘야 한다. 예를 들어, 회사명이나 제품명의 경우, 또 사용자 키워드의 경우 다양한 면에서의 엔티티가 존재하게 된다. 사용자가 관심 있는 엔티티가 제품명이야? 브랜드야? 속성이야?에 따라 다양한 입력이 있을 수 있는데, 이것을 사전에 전부 커버할 수 있는 방법은 없다.
만약, 비즈니스적으로 위 엔티티 스키마 외에 더 많은 엔티티가 필요하다면 스키마에 해당하는 정보를 채워줘. 해당 정보가 없으면 null 또는 빈 문자열로 남겨줘. 라는 형태로 -, 아래의 경우 Slot에 가격, 스토어, 지역, 성별, 채널을 추가한 구조다.
{
"keyword": "다이소 전동 눈썹정리기 추천",
"entities": {
"brand": "다이소",
"product_name": "전동 눈썹정리기",
"category": ["눈썹정리기", "전동제품"],
"attribute": ["저가형", "휴대용"],
"intent": "추천",
"price": null,
"store": "다이소",
"region": null,
"target_gender": "여성",
"channel": "검색"
}
}따라서 보통 핵심 엔티티만 정리하고, 나머지는 확장식 설계 접근이 실용적이다. 특히 그래프 구조의 경우 새로운 노드, 속성, 관계를 나중에 붙이는 것이 매우 쉽기 때문이다.
특정 사용자 질의에 대해서 해당되는 그래프디비가 존재하지 않을 경우 2가지로 경우를 생각해 볼 수 있다. 먼저, 해당되는 답이 없다가 있을 것이고, 다른 하나는 사용자 질문을 구조화 한 상태에서 스키마에 기반해 그래프를 자동으로 확장할 수도 있다. 그런데 이럴 경우 Hallucination 가능성이 충분히 존재하게 됨. 그렇기 때문에 비즈니스적으로 크리티컬한 사용자를 대상으로 하는 경우에는 LLM에게 “모르면 확장하지 말라”고 명시하는 것도 방법이다.
그래프 스키마의 제한
문장으로 주고, LLMGraphTransformer로 노드+관계로 구성된 그래프 문서를 만들 수 있음을 살펴 보았다. 만약 그래프 스키마를 정의하지 않고 생성할 경우, LLM은 런타임에 추출할 정보를 결정하고 이로 인해서 동일한 문장을 입력해도 출력에 차이가 발생할 수 있다. 즉, 스키마가 없으면 GPT가 “자기 생각대로” 뽑는다→ 실행할 때마다 관계명, 라벨, 노드 수 등이 달라질 수 있음.
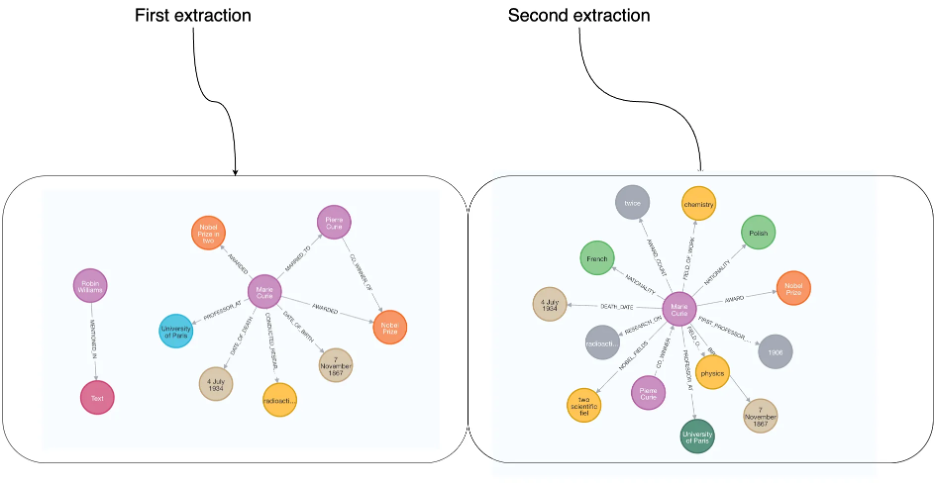
신뢰도와 일관성을 높이기 위한 그래프 스키마를 제한하는 방법을 보는데, 먼저 노드들의 정의(선언)을 할 수 있다. 즉, 이 노들들만 추출하라고 LLM에 요청하는 것. 예를 들어 Person, Organization 같은 핵심 개체만 추출하게끔 유도. 이렇게 되면 추출 전반에 걸쳐서 일관성이 유지가 된다.
allowed_nodes = [“Person”, “Organization”, “Location”, “Award”, “ResearchField”]
nodes_defined = LLMGraphTransformer(llm=llm, allowed_nodes=allowed_nodes)
이제 모델은 5가지 라벨로만 노드를 만들 수 있고 불필요한 라벨은 추출하지 않도록 제어가 가능하다. 그럼에도 완벽한 통제는 불가하고 안정도와 일관성이 높아지는 것이다. 릴레이션 타입은 제한되지 않았기에 관계타입도 다양하게 나올 수 있다.
2번째로 Relationships 라벨도 아래와 같이 제한할 수 있다.
allowed_relationships = ["SPOUSE", "AWARD", "FIELD_OF_RESEARCH", "WORKS_AT", "IN_LOCATION"]
rels_defined = LLMGraphTransformer(
llm=llm,
allowed_nodes=allowed_nodes,
allowed_relationships=allowed_relationships
)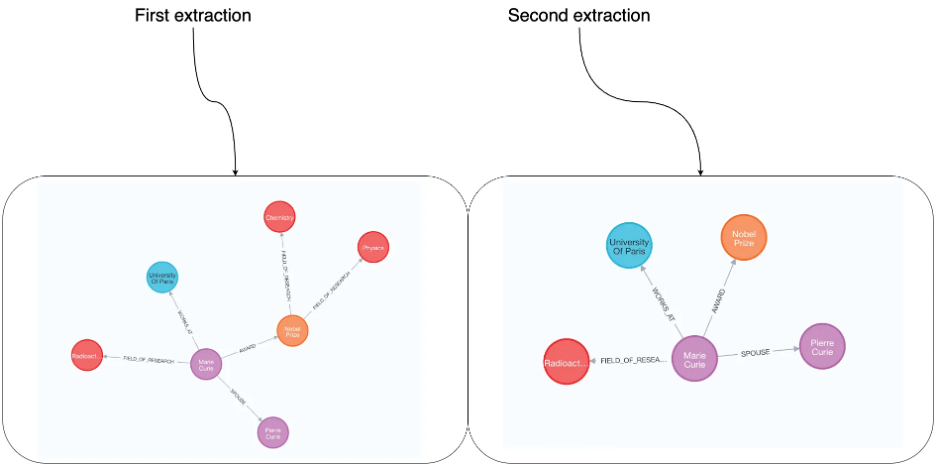
노드 라벨과 릴레이션 두개 모두 선언할 경우, 반복되어도 출력의 일관성이 훨씬 더 높아진다.
마지막으로 속성을 제한하는 방법인데, 추출할 속성은 자유롭게 선택하게 설정한 예는 아래와 같다.
props_defined = LLMGraphTransformer(
llm=llm,
allowed_nodes=allowed_nodes,
allowed_relationships=allowed_relationships,
node_properties=node_properties,
relationship_properties=relationship_properties
)반대로 선언할 경우에는 node_properties=[“birth_date”, “death_date”] 형태로 허용할 수 있다. 이 경우, 앞에서 노드, 관계, 그리고 속성까지 제한하면 높은 수준의 통제가 가능하나 반대로 중요한 속성 정보가 누락될 가능성이 크다. 그리고 모든 속성은 문자열로만 출력된다.


